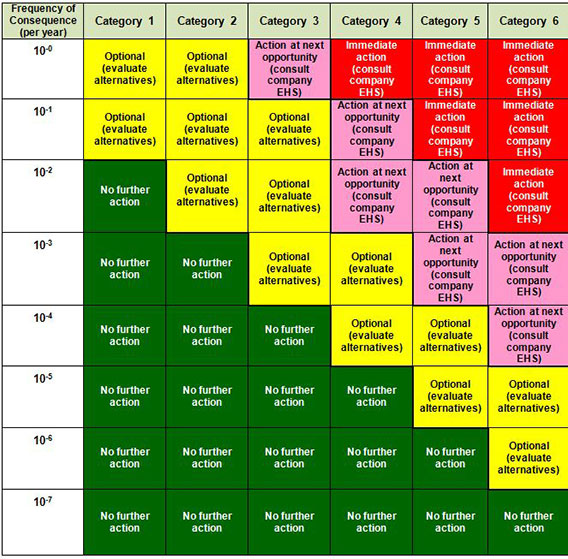
There is a lot of discussion elsewhere on ALARP (and/or ALARA). However, a company can add too many protection layers and invite shortcuts of one or more of the IPLs over the long-term, since staff are pretty sharp at figuring out when the “plumbing is over-tinked”. We advise folks to reach barely tolerable on each scenario and then stop; BUT make sure you find all scenarios during ALL modes of operation (which is the main weakness in most PHAs/HAZOPs that we critique). Not finding a scenario has cause accidents; but we have yet to find an accident for a scenario that had enough properly designed and maintained IPLs to reach barely tolerable reach (that achieved the maximum tolerable risk, sometimes called Target Mitigated Event Likelihood (TMEL)
It is difficult to find a statistical basis for the TMEL for a single fatality. The typical value used by a company is 1/10,000 (or 10-4) per year. If you look at the actual accidents that occur of a very long period of time, I doubt you will find one if there were two IPLs that were properly maintained and properly designed for the scenarios. As a first step, just try to find an overpressure accident that had a properly designed and maintained PSV alone (one IPL). (Yes, I know there are rare scenarios where a PSV is not a good IPL again overpressure; I have helped model a few of those on the early 1990s; I’m not referring to those; I’m referring to cases where a PSV is a true IPL, meeting the definition of an IPL as stated in LOP [2001]). So, from this data, one could say that it appears that 10-2 per year or 10-3 per year is statistically justifiable, given there have been more than one million plant years of operation to date. I tend to agree with 10-3 per year (though some folks jeer when I say that in public or here). Remember, our first goal should be to FIND all scenarios and then QUALITTAIVELY ensure each scenario has sufficient true IPLs; if you miss a scenario during startup mode of operation (as opposed to continuous or normal mode where most PHAs /HAZOPs are overly focused), then those undiscovered scenarios will dominate the risk… note that 80% of major process catastrophes continue to occur during non-normal (such as startup and online maintenance) modes of operation.
Some folks point to the background accidental risk death of society as a good standard; and many of the early risk assessments in the US pointed to that risk, which is dominated in the US by road accidents which run about 1/10,000 (10-4) per year for accidental death when driving. But how is that comparable to the risk of working in a highly structured chemical process plant? On the highway, you may have control of your human factors and mechanical features, but there are truly No IPLs for most accidents (the driver controls most of the safeguards) and you do not control the other drivers or the elements. Whereas in a chemical process, all aspects of process excursions are under our control (to the extent possible given random failures), we control the human factors of all of the players to much greater extent than on the roadways, and we have some true IPLs.
In summary, the range of values for TMEL in the literature is 10-3 to 10-5 per year; our advice it pick 10-3 per year for now and then make sure you find ALL scenarios first, by performing a process hazard analysis (e.g., using HAZOP, etc.) of normal mode of operation and of deviations of procedural steps for startup, shutdown, and online maintenance tasks (all non-normal modes of operation). Then, once you find the scenarios for ALL modes and determine which IPLs are valid for each of those modes of operation (a great many IPLs are only designed and valid for normal mode of operation), and once you achieve tolerable risk for each scenario (either qualitatively or using LOPA with a TMEL = 10-3 per year), then you can look at reasons to lower the TMEL over the long term. We need to first focus on stopping the deaths that are occurring during non-routine modes of operations; many of these scenarios are NOT being found.


{kind=link}
{kind=link}